It is evident that clear and detailed text prompts significantly enhance the quality of generated outputs. Furthermore, increasing the
value of num_inference_step typically leads to better results. To ensure the reproducibility of these outcomes, the random seed is
fixed at 1.
Part 1: Single-Step Denoising UNet
Objective: Train a UNet for single-step denoising using MNIST dataset.
1.1 Implementing the Forward Process
In this part, the goal is to implement the forward diffusion process, which progressively adds noise to a clean image.
The forward process involves sampling from a Gaussian distribution with a variance that increases over time. The image
is scaled by the cumulative product of alphas (alphas_cumprod), where smaller timesteps result in an image close to the
original (less noise) and larger timesteps result in more noise. The task is to write the function noisy_im = forward(im, t),
which takes a clean image and a timestep t as inputs, and returns the noisy image at that timestep. The test image, Campanile,
is resized to 64x64, and the function is applied to generate noisy images at timesteps [250, 500, 750], which is displayed to
observe the progression of noise.

original

Noisy at t=250

Noisy at t=500

Noisy at t=750
1.2 Classical Denoising
In this part, the goal is to apply classical denoising techniques, specifically Gaussian blur filtering, to the noisy images
generated at timesteps [250, 500, 750]. Gaussian blur is a smoothing filter that attempts to reduce noise by averaging pixels
within a local neighborhood, but it is unlikely to produce good results due to the complexity of noise in the diffusion process.
The task is to apply the torchvision.transforms.functional.gaussian_blur function to each noisy image and display the denoised
images with the corresponding noisy images. This will illustrate the challenge of denoising these images using traditional methods.
Noisy Image at t=250
Noisy Image at t=500
Noisy Image at t=750

Gaussian Blur Denoising
Image at t=250

Gaussian Blur Denoising
Image at t=500

Gaussian Blur Denoising
Image t=750
1.3 One-Step Denoising
Part 1.3 involves using the pretrained UNet model to denoise noisy images generated at timesteps [250, 500, 750]. The model
estimates the noise in the image based on the timestep and a provided text prompt embedding. The noisy image is passed through
the UNet to predict the noise, which is then removed to recover an estimate of the original image. The denoised image, along
with the original and noisy images, are visualized for comparison.
Original
Noisy Image at t=250
Noisy Image at t=500
Noisy Image at t=750
Original

One Step Denoising
Image at t=250

One Step Denoising
Image at t=500

One Step Denoising
Image t=750
The U-Net can be effective to some extent, but as 𝑡 increases, the sampling results deteriorate.
1.4 Iterative Denoising
Part 1.4 focuses on implementing iterative denoising for diffusion models. Instead of running the model 1000 times,
the process can be sped up by skipping steps. The goal is to create a list of timesteps (strided_timesteps), starting at the
noisiest image and reducing the noise with Unet step by step. The formula for each denoising step involves a interpolation between
the noisy image and a clean image estimate, adjusting for the noise at each timestep.

Noisy Image at t=690

Noisy Image at t=540

Noisy Image at t=390

Noisy Image at t=240

Noisy Image at t=90
Original

Iterative Denoising
Image

One Step Denoising
Image

Gaussian Blurred
Denoising Image
1.5 Diffusion Model Sampling
Part 1.5 involves using the iterative_denoise function to generate images from scratch by denoising random noise. By setting
i_start = 0 and initializing the image with pure noise, the model progressively refines the noisy image into a coherent result.
The task requires generating 5 images based on the prompt "a high quality photo."

Sample 1

Sample 2

Sample 3

Sample 4

Sample 5
1.6 Classifier-Free Guidance (CFG)
Part 1.6 focuses on improving image quality through Classifier-Free Guidance (CFG). CFG enhances the diffusion process by
computing both conditional and unconditional noise estimates. The final noise estimate is a weighted combination of these
two, by using model_output = scale * noise_est + (1 - scale) * uncond_noise_est. This technique improves the quality of generated
images but reduces their diversity.

Sample with CFG 1

Sample with CFG 2

Sample with CFG 3

Sample with CFG 4

Sample with CFG 5
The sampling results using CFG are much better than the previous sampling results.
1.7 Image-to-image Translation
Part 1.7 focuses on image-to-image translation using the diffusion model with Classifier-Free Guidance (CFG). The goal is to take a noisy
version of a test image and iteratively denoise it, gradually making the image resemble the original with varying levels of noise.
This process is based on the SDEdit algorithm, which forces a noisy image back onto the manifold of natural images, allowing for creative edits.
Test Image

SDEdit i_start=1

SDEdit i_start=3

SDEdit i_start=5

SDEdit i_start=7

SDEdit i_start=10

SDEdit i_start=20
Original
Own Image

SDEdit starting from different i_start

Original

SDEdit starting from different i_start

Original
1.7.1 Editing Hand-Drawn and Web Images
Part 1.7.1 focuses on applying the image-to-image translation procedure to hand-drawn or non-realistic images, such as sketches or web images,
to project them onto the natural image manifold.
Web Image

Image at i_start=1

Image at i_start=3

Image at i_start=5

Image at i_start=7

Image at i_start=10

Image at i_start=20

Image from Website

Image at i_start=1

Image at i_start=3

Image at i_start=5

Image at i_start=7

Image at i_start=10

Image at i_start=20

Image from Website
Hand Drawn Image

Image at i_start=1

Image at i_start=3

Image at i_start=5

Image at i_start=7

Image at i_start=10

Image at i_start=20

Hand Drawn Image

Image at i_start=1

Image at i_start=3

Image at i_start=5

Image at i_start=7
Image at i_start=10

Image at i_start=20

Hand Drawn Image
1.7.2 Inpainting
In part 1.7.2, the task is to implement inpainting using the diffusion model. The goal is to take an image 𝑥0, a binary mask 𝑚,
and create a new image that retains the content of 𝑥0 where 𝑚=0 (the unmasked areas), but fills in the masked areas (where 𝑚=1)
with new content generated by the model. The specific method is to replace the parts with a mask value of 0 with the corresponding
noisy image from the original image at time step t after each denoising step.
Test Image
Original

Mask

To Replace

Inpainting
Own Image

Original

Mask

To Replace

Inpainting

Original

Mask

To Replace

Inpainting
1.7.3 Text-Conditional Image-to-image Translation
In part 1.7.3, the task is to apply text-conditional image-to-image translation. This is similar to the previous SDEdit approach but now includes
a text prompt to guide the process. The goal is to generate images that not only project onto the natural image manifold but also incorporate
the characteristics of the provided text prompt.
Test Image

Text-Conditional Image-to-image Translation ("a rocket ship")
Original
Own Image

Text-Conditional Image-to-image Translation ("an oil painting of a snowy mountain village")

Original

Text-Conditional Image-to-image Translation ("a photo of a dog")

Original
1.8 Visual Anagrams
In part 1.8, the task is to implement Visual Anagrams—a technique that creates optical illusions using diffusion models.
The goal is to generate an image that appears as one thing when viewed in one orientation but transforms into something
completely different when flipped upside down. The method involves estimating the noise of the image at each time step t
and its vertically flipped version. The estimated noise is obtained by averaging the original noise with the flipped
version after it is reversed.
Example

An Oil Painting of an Old Man

An Oil Painting of People around a Campfire
More Examples

A Photo of A Dog

A Man Wearing A Hat

A Photo of A Hipster Barista

A Lithograph of Waterfalls
1.9 Hybrid Images
In part 1.9, the task is to create Hybrid Images using diffusion models. Hybrid images combine the low-frequency content
from one image with the high-frequency content from another, producing an image that looks like one thing from a distance
and something completely different up close. The estimated noise is obtained by combining the low-frequency noise estimation
of one image with the high-frequency noise estimation of another image.
Example

Hybrid image of a skull and a waterfall
More Examples

Hybrid image of a man and a skull

Hybrid image of a man and a dog
Part 2: Training a Diffusion Model
Objective: Train a time-conditioned UNet to iteratively denoise images.
In the second part, a time-conditioned UNet is trained to iteratively denoise images as part of a diffusion model framework.
The key idea is to generate a sequence of noisy images by progressively adding Gaussian noise,
then train the model to reverse this process step by step. The UNet incorporates a time-conditioning mechanism,
allowing it to denoise images based on the noise level at a given timestep. The model is trained to minimize the
difference between its predictions and the clean images, enabling it to reconstruct high-quality samples from noisy inputs.
Training progress is tracked using a loss curve, while the quality of generated images is evaluated by sampling outputs at
different stages of training. These results illustrate the model's ability to iteratively improve the image quality through
the denoising process.
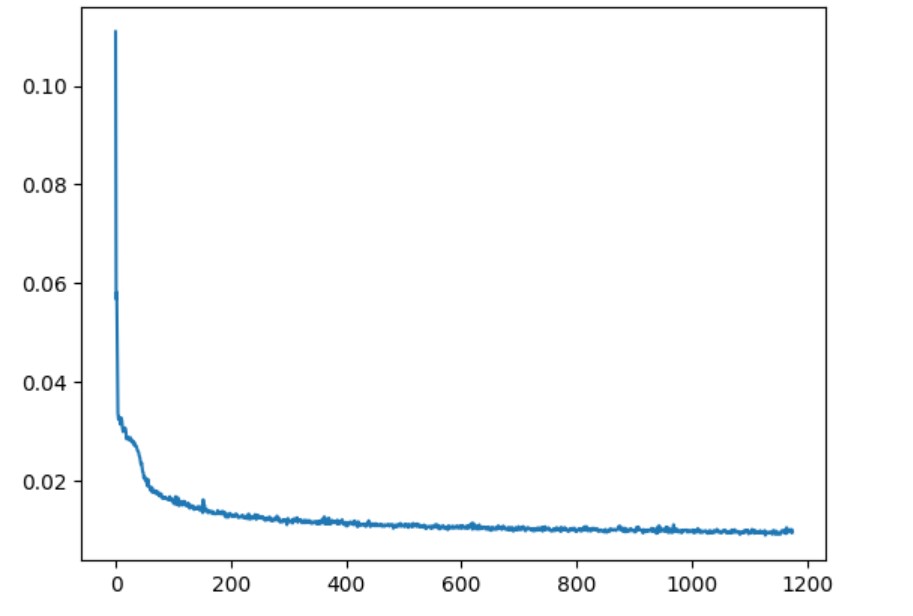
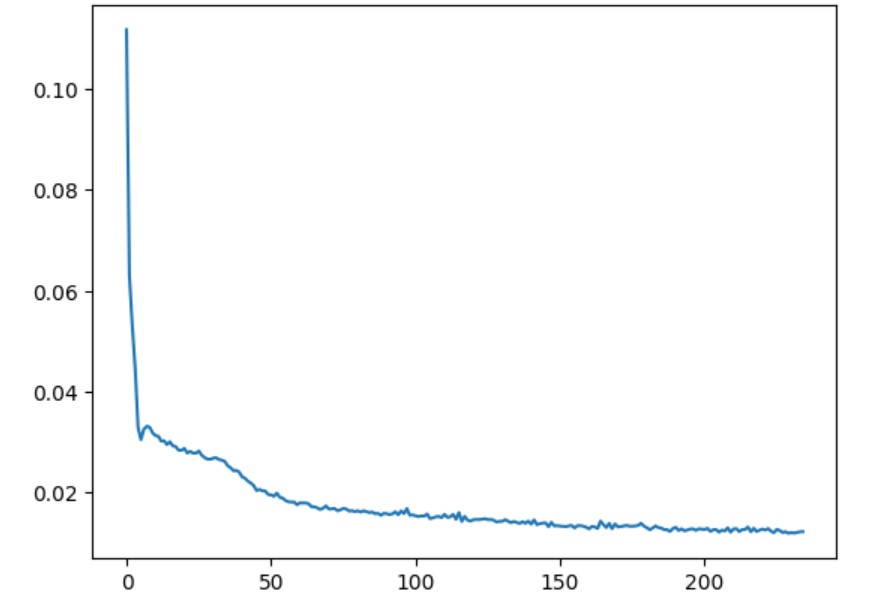
Training Loss Curve
Time-Conditioned UNet training loss curve with epoch=5
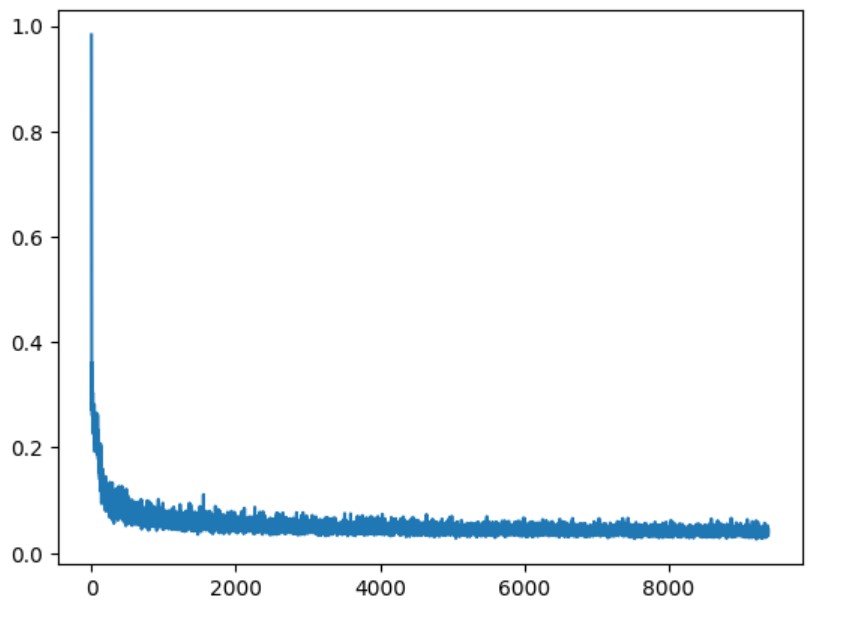
Time-Conditioned UNet training loss curve with epoch=20
Sampling Results

Diffusion Results After 5 Epochs

Diffusion Results After 20 Epochs
Class-Conditioned UNet
Objective: Train a class-conditioned UNet with classifier-free guidance.
The final part of the project extends the diffusion model by introducing class conditioning, where the model is guided to generate outputs corresponding to specific classes.
This is achieved by incorporating one-hot encoded class labels as an additional input to the UNet model.
During training, the model learns to associate noisy images with their respective class labels,
allowing it to produce class-specific results during sampling. To further enhance the generated outputs,
classifier-free guidance is applied, encouraging the model to better focus on class-related features.
The effectiveness of this approach is evaluated by generating samples for each class at different training stages,
with visualizations showcasing the diversity and accuracy of the generated images.
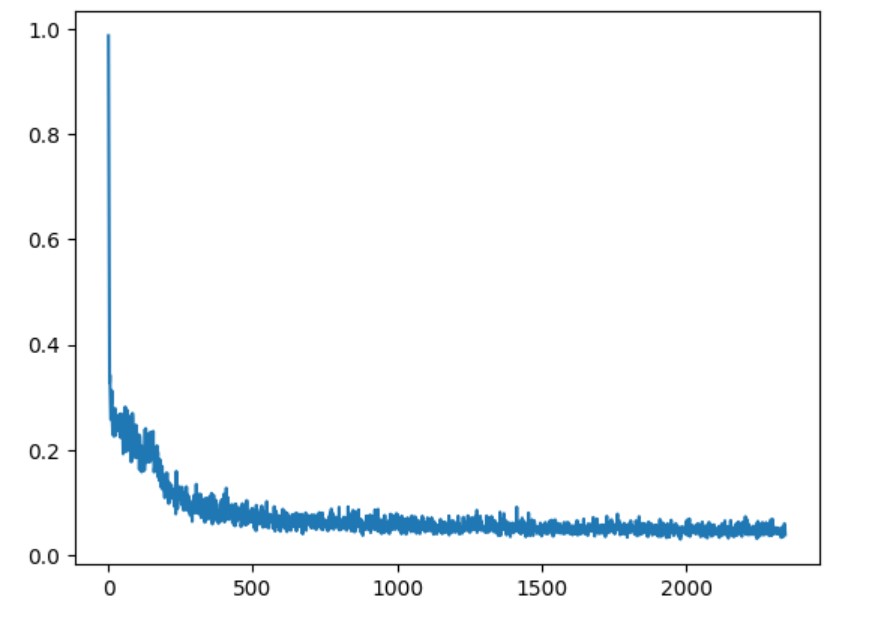
Training Loss Curve
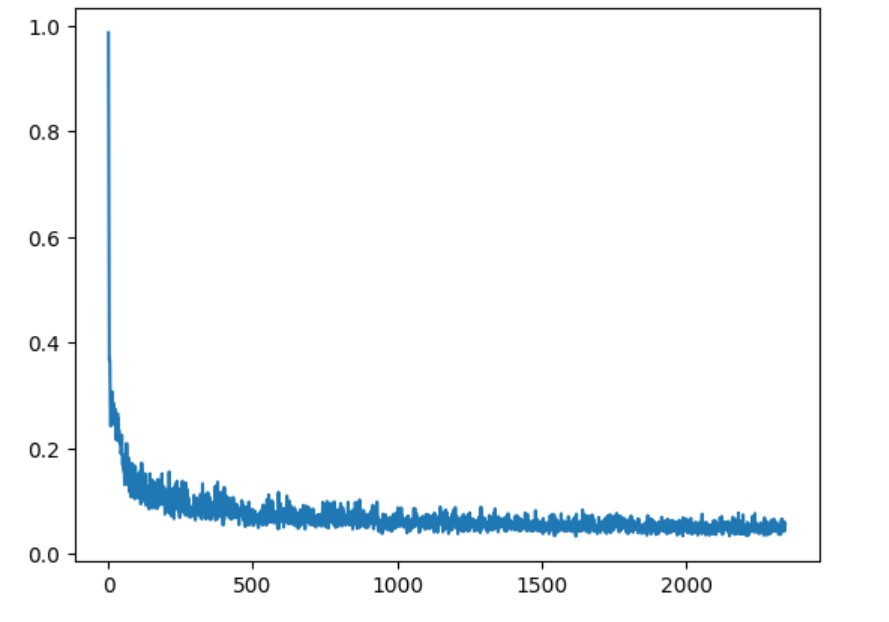
Class-Conditioned UNet training loss curve with epoch=5
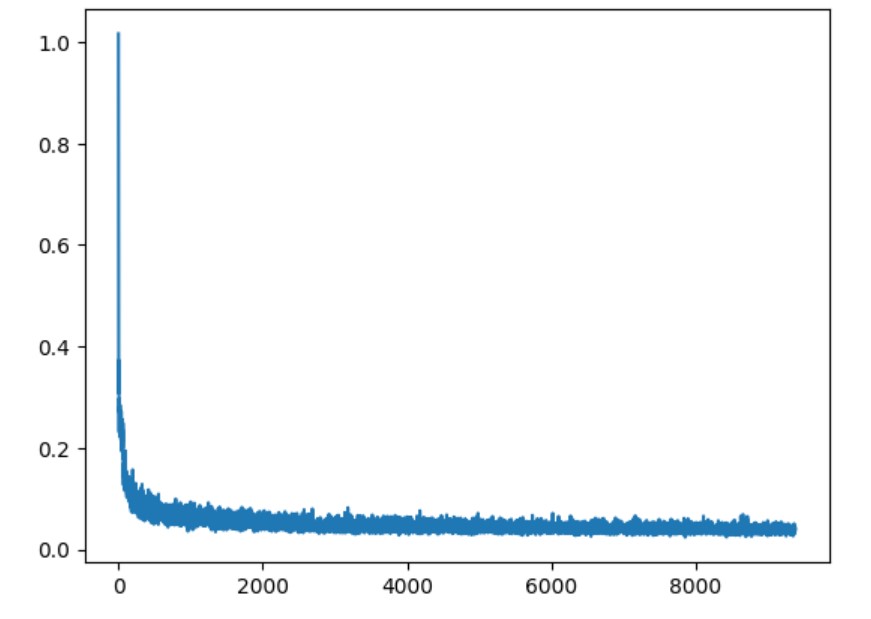
Class-Conditioned UNet training loss curve with epoch=20
Sampling Results

Diffusion Results After 5 Epochs

Diffusion Results After 20 Epochs